What is Standard Deviation?
I'll be honest. Standard deviation is a more difficult concept than the others we've covered. And unless you are writing for a specialized, professional audience, you'll probably never use the words "standard deviation" in a story. But that doesn't mean you should ignore this concept.
The standard deviation is kind of the "mean of the mean," and often can help you find the story behind the data. To understand this concept, it can help to learn about what statisticians call "normal distribution" of data.
A normal distribution of data means that most of the examples in a set of data are close to the "average," while relatively few examples tend to one extreme or the other.
Let's say you are writing a story about nutrition. You need to look at people's typical daily calorie consumption. Like most data, the numbers for people's typical consumption probably will turn out to be normally distributed. That is, for most people, their consumption will be close to the mean, while fewer people eat a lot more or a lot less than the mean.
When you think about it, that's just common sense. Not that many people are getting by on a single serving of kelp and rice. Or on eight meals of steak and milkshakes. Most people lie somewhere in between.
If you looked at normally distributed data on a graph, it would look something like this:

The x-axis (the horizontal one) is the value in question... calories consumed, dollars earned or crimes committed, for example. And the y-axis (the vertical one) is the number of datapoints for each value on the x-axis... in other words, the number of people who eat x calories, the number of households that earn x dollars, or the number of cities with x crimes committed.
Now, not all sets of data will have graphs that look this perfect. Some will have relatively flat curves, others will be pretty steep. Sometimes the mean will lean a little bit to one side or the other. But all normally distributed data will have something like this same "bell curve" shape.
The standard deviation is a statistic that tells you how tightly all the various examples are clustered around the mean in a set of data. When the examples are pretty tightly bunched together and the bell-shaped curve is steep, the standard deviation is small. When the examples are spread apart and the bell curve is relatively flat, that tells you you have a relatively large standard deviation.
Computing the value of a standard deviation is complicated. But let me show you graphically what a standard deviation represents...
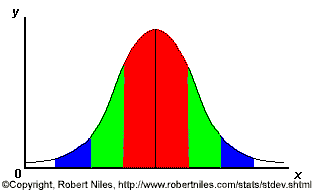
One standard deviation away from the mean in either direction on the horizontal axis (the two shaded areas closest to the center axis on the above graph) accounts for somewhere around 68 percent of the people in this group. Two standard deviations away from the mean (the four areas closest to the center areas) account for roughly 95 percent of the people. And three standard deviations (all the shaded areas) account for about 99 percent of the people.
If this curve were flatter and more spread out, the standard deviation would have to be larger in order to account for those 68 percent or so of the people. So that's why the standard deviation can tell you how spread out the examples in a set are from the mean.
Why is this useful? Here's an example: If you are comparing test scores for different schools, the standard deviation will tell you how diverse the test scores are for each school.
Let's say Springfield Elementary has a higher mean test score than Shelbyville Elementary. Your first reaction might be to say that the kids at Springfield are smarter.
But a bigger standard deviation for one school tells you that there are relatively more kids at that school scoring toward one extreme or the other. By asking a few follow-up questions you might find that, say, Springfield's mean was skewed up because the school district sends all of the gifted education kids to Springfield. Or that Shelbyville's scores were dragged down because students who recently have been "mainstreamed" from special education classes have all been sent to Shelbyville.
In this way, looking at the standard deviation can help point you in the right direction when asking why information is the way it is.
Of course, you'll want to seek the advice of a trained statistician whenever you try to evaluate the worth of any scientific research. But if you know at least a little about standard deviation going in, that will make your talk with him or her much more productive.
Okay, because so many of you asked nicely...
Here is one formula for computing the standard deviation. A warning, this is for math geeks only! Writers and others seeking only a basic understanding of stats don't need to read any more in this chapter. Remember, a
decent calculator or a stats program will calculate this for you...
Terms you'll need to know
x = one value in your set of data
avg (x) = the mean (average) of all values x in your set of data
n = the number of values x in your set of data
For each value x, subtract the overall avg (x) from x, then multiply that result by itself (otherwise known as determining the square of that value). Sum up all those squared values. Then divide that result by (n-1). Got it? Then, there's one more step... find the square root of that last number. That's the standard deviation of your set of data.
Now, remember how I told you this was one way of computing this? Sometimes, you divide by (n) instead of (n-1). It's too complex to explain here. So don't try to go figuring out a standard deviation if you just learned about it on this page. Just be satisfied that you've now got a grasp on the basic concept.
The more practical way to compute it...
In Microsoft Excel, type the following code into the cell where you want the Standard Deviation result, using the "unbiased," or "n-1" method:
=STDEV(A1:Z99) (substitute the cell name of the first value in your dataset for A1, and the cell name of the last value for Z99.)
Or, use...
=STDEVP(A1:Z99) if you want to use the "biased" or "n" method.
Read the rest of Robert Niles' Statistics Every Writer Should Know.
If these ad-free lessons helped you, would you consider sending a buck or two to Robert Niles?